Comment entraîner et adapter un grand modèle de langage (LLM) pour l’entreprise : comprendre les étapes et les opportunités.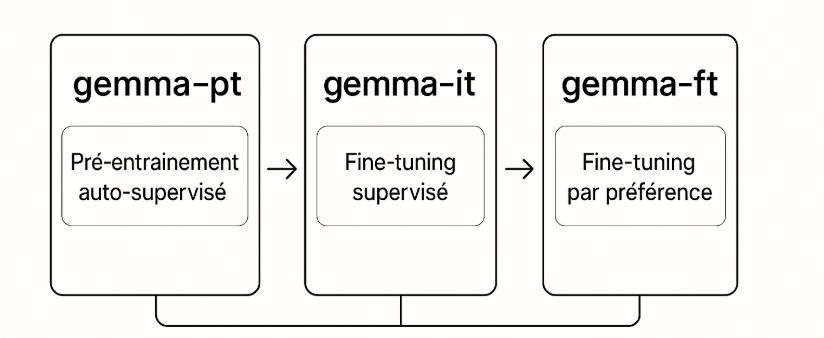
Les grands modèles de langage (LLM) transforment la manière dont les organisations exploitent leurs données, servent leurs clients et assistent leurs collaborateurs. De l’assistant conversationnel au copilote métier, leur potentiel est considérable. Pour passer d’un modèle générique à un outil réellement pertinent, il est essentiel de comprendre les étapes d’entraînement et les leviers disponibles pour le fine-tuning.
La nomenclature de Google autour de la famille Gemma constitue un repère utile pour organiser ces étapes et structurer une feuille de route d’adaptation en entreprise.
Les trois grandes étapes d’entraînement (nomenclature Gemma)
gemma--pt : pré-entraînement auto-supervisé
- Objectif : apprendre la structure de la langue sur d’immenses corpus (modélisation du langage).
- Résultat : un modèle « brut » capable de compléter/raisonner, mais pas encore à l’aise pour suivre des consignes précises.
- Intérêt pour l’entreprise : excellente base pour l’expérimentation rapide et les spécialisations ultérieures.
gemma--it : fine-tuning supervisé (SFT)
- Objectif : apprendre à suivre des instructions avec des paires instruction → réponse de haute qualité.
- Résultat : un modèle plus utile dans des cas guidés, orienté tâche (résumer, classer, transformer, générer selon un format).
- Intérêt : point de départ courant pour des assistants métier cadrés.
gemma-*-ft : fine-tuning par préférence (RLHF, SimPO, GrPO)
- Objectif : optimiser la qualité perçue et l’alignement en privilégiant certaines réponses (préférences humaines ou simulées).
- Techniques : RLHF, SimPO, GrPO (optimisation sur feedback groupés et critères multiples).
- Résultat : un modèle robuste en conversation, mieux aligné aux politiques internes (sécurité, ton, conformité).
Opportunités techniques et pratiques pour le fine-tuning corporate
1) Adapter un modèle existant aux données métier internes
- Exploiter des corpus propriétaires : documentation technique, procédures, tickets support, contrats, FAQs internes.
- Injecter terminologie, style et contraintes propres à l’organisation.
- Mettre en place une gouvernance des données (qualité, sécurité, traçabilité) et un data curriculum par usage.
2) Tirer parti des techniques modernes (efficience & qualité)
- PEFT / LoRA : n’adapter que de petits modules (low-rank) → grosses économies GPU, déploiements rapides, possibilité de multiples adapters par BU.
- QLoRA / 4-8 bits : quantifier les poids pour entraîner sur des GPU plus modestes tout en conservant la qualité.
- GrPO : aligner sur des préférences collectives (conformité, ton de marque, critères multi-dimensionnels) et agréger des retours de panels internes.
- SimPO : accélérer l’optimisation par préférence avec des signaux simulés quand le feedback humain est coûteux.
3) Accélérer le passage de la R&D au déploiement
- Pipelines reproductibles : préparation des données, entraînement, évaluation, packaging, tests de régression.
- Stratégies de feature-store et de versioning (données, prompts, adapters LoRA) pour faciliter les itérations.
- Observabilité en production : garde-fous, monitoring de dérive, boucles de feedback utilisateur → jeu de données d’amélioration continue.
4) Limiter les coûts & améliorer la performance
- Choisir la taille de modèle adaptée à la tâche (right-sizing) et privilégier PEFT avant le plein fine-tuning.
- RAG (Retrieval-Augmented Generation) pour externaliser la « mémoire » dans un index documentaire plutôt que l’encoder dans les poids.
- Bons réflexes d’inférence : quantification, compilation (TensorRT/ONNX), speculative decoding, batching.
Cas d’usage concrets
- Chatbots internes : helpdesk IT, support, politiques internes, QHSE.
- Recherche sémantique & RAG : interrogation d’une base de connaissances interne en langage naturel, citations et traçabilité.
- Automatisation de processus : tri de tickets, routage, normalisation de champs, rédaction de réponses.
Réflexion critique : pourquoi lancer une optimisation GrPO directement sur la version « pt » ?
La séquence pt → it → ft est logique, mais ce n’est pas une règle absolue. Dans certains contextes, démarrer une optimisation par préférence (p. ex. GrPO) directement depuis la version pt peut être pertinent :
- Éviter les « consignes apprises » non désirées : un
itpublic peut injecter des biais de ton ou de style contraires à la culture d’entreprise. - Alignement plus précoce : GrPO sur
ptcalibre tôt les préférences (sécurité, conformité, concision), avant d’enseigner les tâches spécifiques. - Efficience data : quand peu de données d’instructions internes sont disponibles, des signaux de préférence bien conçus peuvent guider le modèle sans SFT massif.
En pratique, deux voies sont souvent gagnantes :
- pt → it → ft : pour des assistants multi-tâches avec consignes riches.
- pt → ft (GrPO/SimPO) → it ciblé : quand l’alignement culturel/risque prime et que l’on veut maîtriser le ton dès le départ.
Conclusion et perspectives
Les LLM ne sont pas des solutions toutes faites : ce sont des briques puissantes qui doivent être adaptées, orientées et optimisées. En comprenant les trois grandes étapes d’entraînement — pré-entraînement (pt), fine-tuning supervisé (it), fine-tuning par préférence (ft) — les entreprises peuvent mieux planifier leurs investissements.
Les techniques modernes comme LoRA, PEFT ou GrPO offrent des opportunités inédites pour créer des modèles internes performants à moindre coût. L’enjeu est désormais de passer de l’expérimentation à l’industrialisation, en construisant des pipelines robustes et gouvernés.
La recommandation clé : partir d’un modèle existant, cibler le fine-tuning sur des données métier pertinentes, et choisir le bon moment pour appliquer des optimisations par préférence. C’est cette combinaison qui permettra aux entreprises d’exploiter pleinement la révolution LLM, tout en gardant le contrôle stratégique sur leurs usages.